
The final filter in Thor’s armoury is a rather special one named a Formant filter, so-called because it imposes formants on any signal passed through it. But what are formants, and why would you want to impose them on anything?
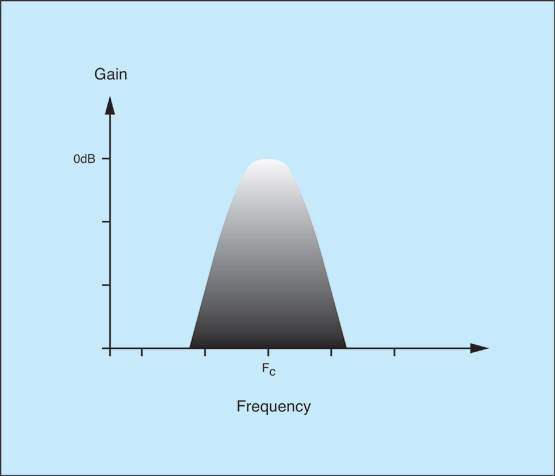
Let’s start to answer this by reminding ourselves of the four types of filters most commonly found in synthesizers. These are the low-pass filter (figure 1) the high-pass filter (figure 2) the band-reject or ‘notch’ filter (figure 3) and the band-pass filter (figure 4). Our journey into formant synthesis begins with the fourth of these.




A simple 6dB/oct band-pass filter is a fairly weak shaper of a signal, but if you place a number of these with the same centre frequency in series, the width of the pass-band becomes narrower and narrower until only a limited range of frequencies is allowed through. (Figures 5 and 6.)

Now imagine the case in which you place, say, three of these multiple band-pass filters in parallel. If you set the cut-off frequency to be different for each signal path, you obtain three distinct peaks in the spectrum (see figure 7) and the filters attenuate any signal lying outside these bands. As you can imagine, any sound filtered in this way adopts a distinctive new character.
(A similar result can be obtained using parallel peaking filters or even low-pass and high-pass filters with high resonance values, and a number of venerable keyboards in the 1970s used architectures based on these. Although not strictly equivalent, the results look similar and for many synthesis purposes are interchangeable.)

If we wanted to pursue this path further, it would take us into a whole new domain of synthesis called physical modeling. This is because the characteristic resonances of acoustic instruments – the bumps in the instruments’ spectral shapes – are recognisable from one instrument to the next. For example, all violas are of similar shape, size, and construction, so they possess similar resonances and exhibit a consistent tonality that allows your ears to distinguish them from say, classical guitars generating the same pitch. It therefore follows that imitating these resonances is a big step forward toward realistic synthesis. Today, however, we’re going to restrict ourselves to the special case of this that is sometimes called ‘vocal synthesis’.
The Human Voice
Because you share the architecture of your sound production system with billions of other people, it’s safe to say that all human vocalizations – whatever the language, accent, age or gender – share certain acoustic properties. To be specific, we all push air over our vocal cords to generate pitched signals, and we can tighten and relax these cords to change the pitch that we produce. Furthermore, we all produce broadband noise.
The pitched sounds are generated deep in our larynx, so they must pass through our throats, mouths, and noses before they reach the outside world through our lips and nostrils. And, like any other cavity, this ‘vocal tract’ exhibits resonant modes that emphasise some frequencies while suppressing others. In other words, the human vocal system comprises a pitch-controlled oscillator, a noise generator, and a set of band-pass filters! The resonances of the vocal tract and the spectral peaks that they produce are the formants that I keep referring to, and they make it possible for us to differentiate different vowel sounds from one another. (Consonants are, to a large degree, noise bursts shaped by the tongue and lips and, in general, you synthesise these using amplitude contours rather than spectral shapes.)
Table 1 shows the first three formant frequencies for some common English vowels spoken by a typical male adult. As you can see, they do not follow any recognisable harmonic series, and are distributed in seemingly random fashion throughout the spectrum.

Given table 1 and a set of precise filters you might think that you should be able to create passable imitations of these sounds but, inevitably, things are not quite that simple. It’s not just the centre frequencies of the formants that affect the quality of the sound, but also the narrowness of their pass-bands (their Qs) and their gains. So we can extend the information in table 1 to create formants that are more accurate. Let’s take “ee” as an example… (See table 2).

This is an improvement, but it isn’t the end of the story, because the sound generated by a set of static band-pass filters is, umm… static, whereas human vowel sounds are not. To undertake true speech synthesis, we need to make the band-pass filters controllable, applying controllers to all of their centre frequencies, Qs and gains. Unfortunately, this is beyond the scope of this tutorial; so let’s now turn our attention to creating vocal-like sounds using the Formant Filters in Thor.
Creating a choral patch
Thor’s Formant Filter imposes four peaks upon any wide-band signal fed through it, and we can see these if we apply white noise to its input and view its output using a spectrum analyser. You can move the peaks by adjusting the X and Y positions and the Gender knob, but the interactions between these are too complex to describe here. So instead, I created the simple patch in figure 8, and used this to capture four images and four audio samples, one of each taken at each corner of the X/Y display, all with the Gender knob at its mid position. You see the results in figures 9 to 12, and hear them in sounds #1 to #4.

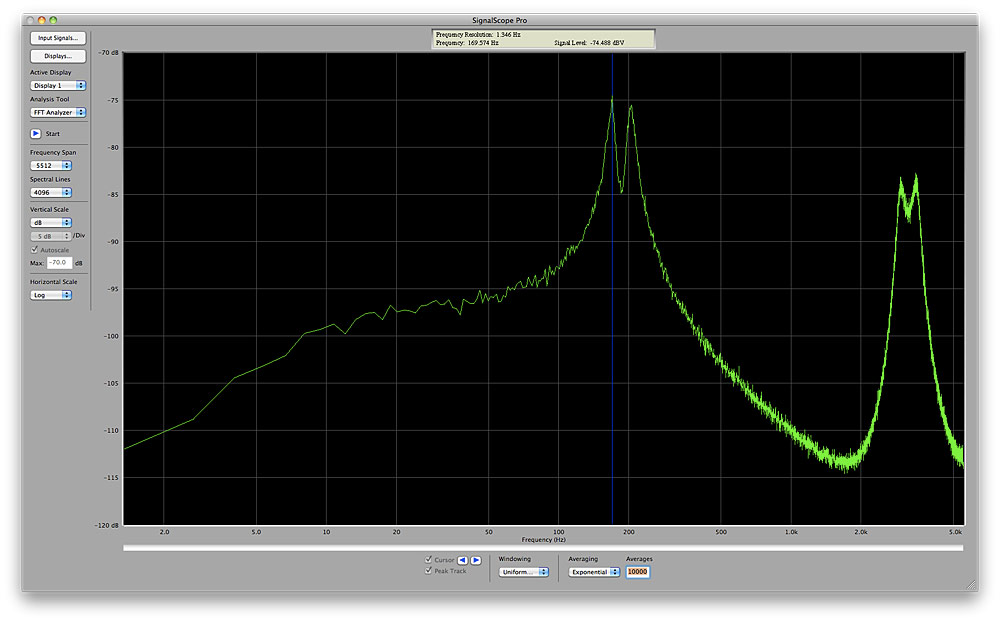
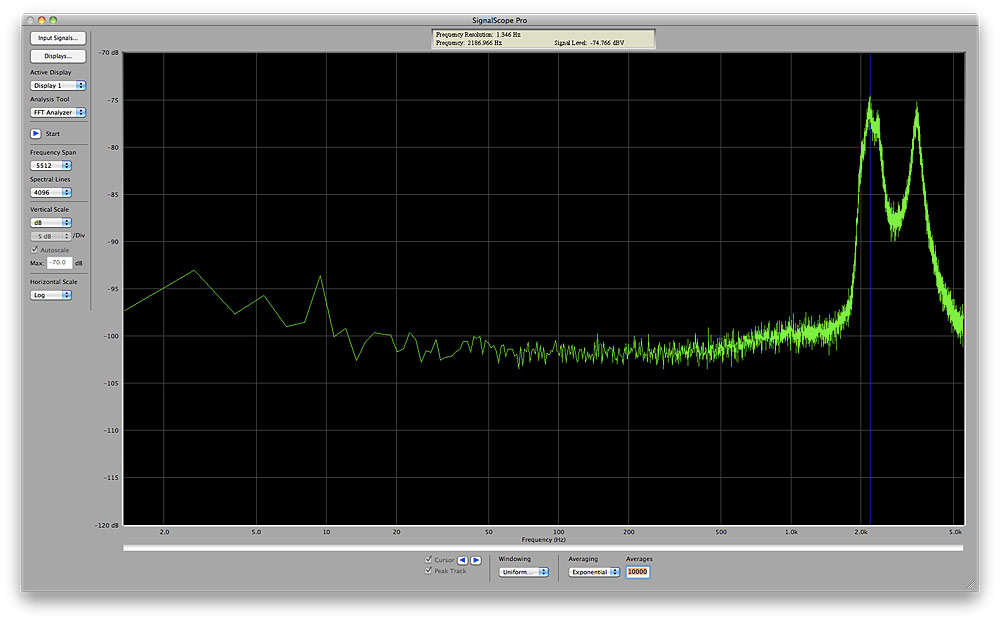
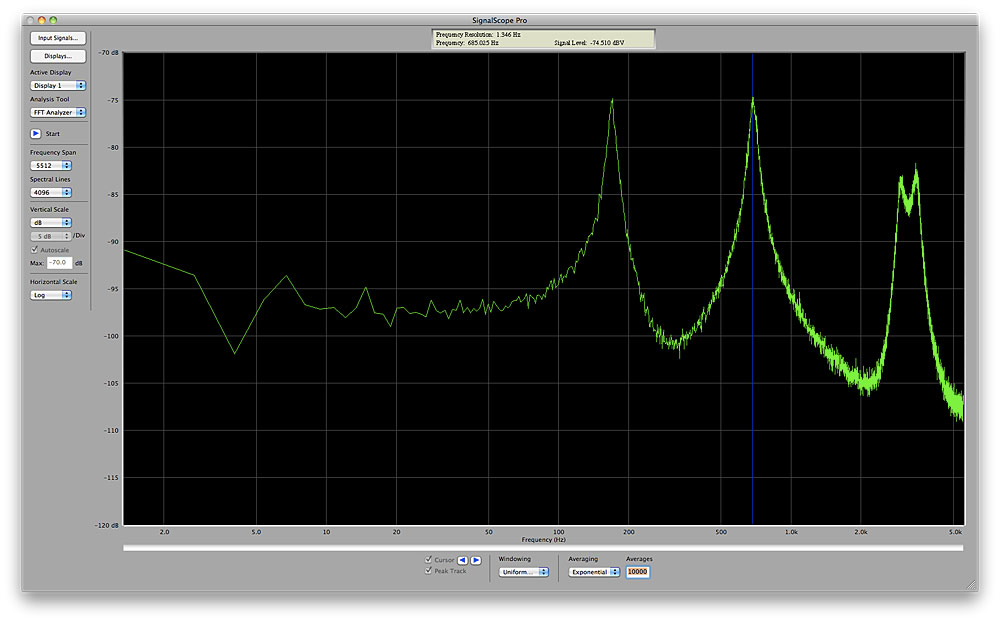

These responses don’t imitate the formants of a human voice in a scientifically accurate way but they are nonetheless quite capable of conveying the impression of a human voice if we replace the noise at the input with a signal that is closer to that generated by the vocal cords. I have chosen a pulse wave with a value of 23 (a duty cycle of about 18%) and shaped the output with a gentle ASR amplitude contour. With no effects applied, the patch looks like figure 13, and you can hear it in sound #5:

(Click to enlarge)
Now let’s apply the Formant Filter. I’ve inserted this into the Filter 1 slot, set the Gender to a value of 46 and set the X/Y values to 46 and 38. (See figure 14.) There is nothing magical about these numbers; I just happen to like the results that they give, especially when I add additional elements into the patch. You’ll also see that the key tracking is set to its maximum, which means that the spectral peaks move within the spectrum as the pitch changes. This is not strictly accurate but I find that, for this patch, the high notes are too dull if I leave the tracking at zero.
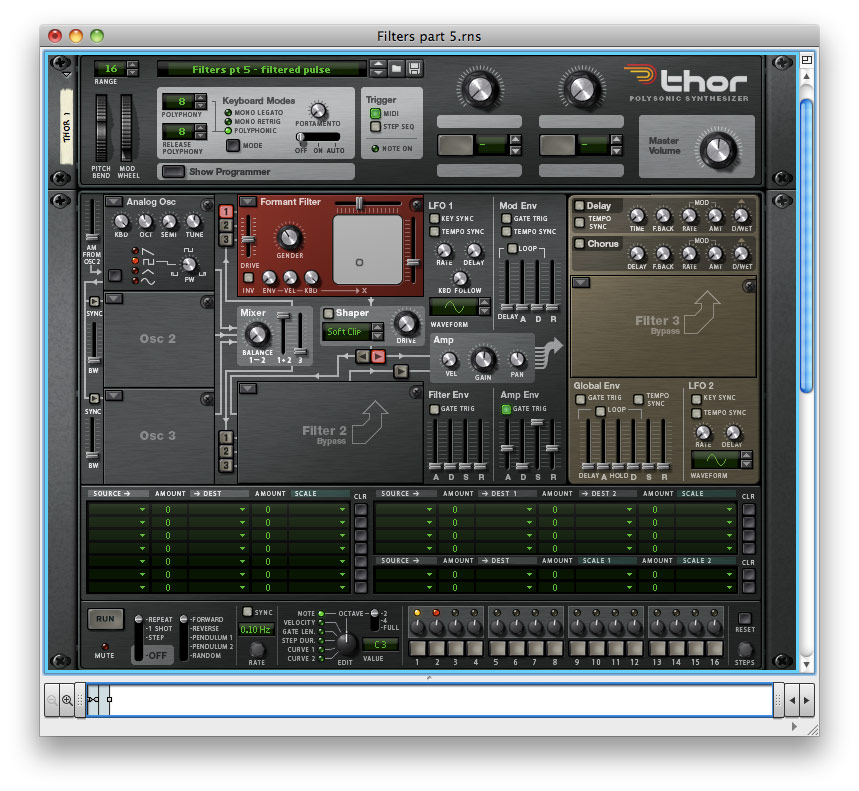
(Click to enlarge)
The patch now exhibits a ‘vocal’ timbre, but it’s rather too static for my taste, so before recording a sample I’ve enhanced it a little by adding some movement to the positions of the filter peaks. I did this by applying a small amount of smoothed random modulation to the X position using LFO1 and by applying a small amount of smoothed random modulation to the Y position using LFO2. The resulting sound (shown in figure 15 and heard in sound #6 ) now has a touch of subtle instability that makes it a little more human than before:
Nonetheless, it sounds like nothing so much as a late-70s vocal synth with the ensemble button switched off. Ah… there’s the clue. Leaving figure 15 untouched and invoking some external ensemble, EQ and reverb results in sound #7 . Luscious!!

(Click to enlarge)
Because the human voice comprises noise as well as tonal signal, we can enhance this still further by adding white noise at low amplitude to the input signal. Figure 16 shows this and, though the difference is again subtle, it can be a worthwhile improvement.

(Click to enlarge)
Of course, you might say that the addition of the external effects made the last sound what it is, and to some extent that would be true, but let’s check what the latest patch sounds like without the Formant Filter:
As you can hear, it has the nuance of a vocal timbre, but at best you might call it a ‘StringVox’ patch. Clearly, it’s the interaction of the filtered sound and the ensemble that achieves the desired effect, which is something that Roland demonstrated more than thirty years ago when they released the wonderful VP-330 Vocoder Plus, whose unaffected vocal sound was little more than a nasal “aah” but whose ensemble defined the choral sounds of the late-70s and early 80s.
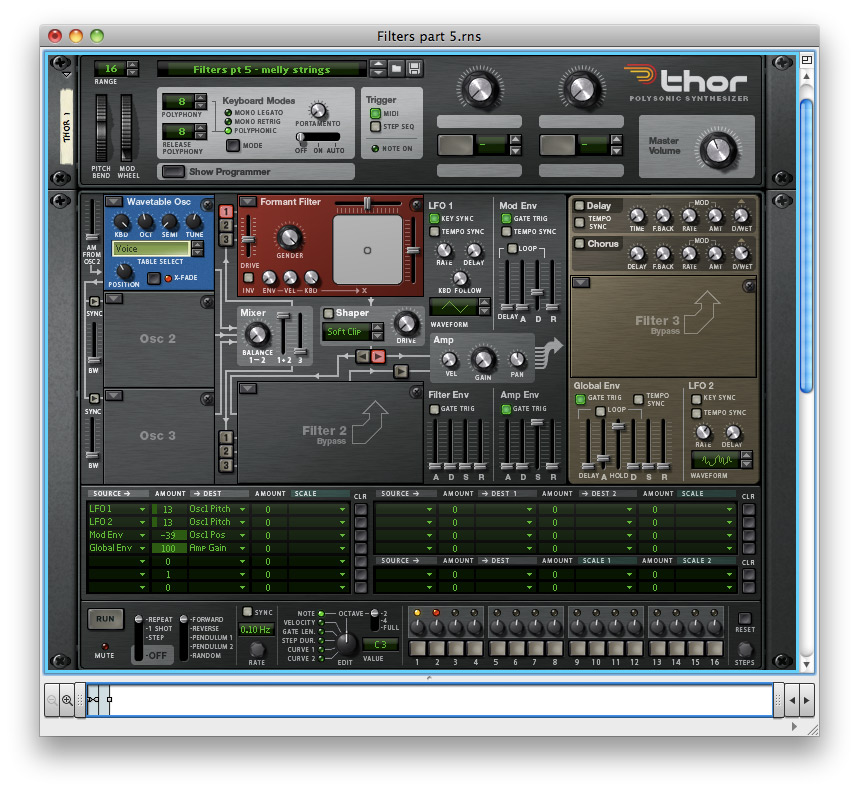
Now let’s ask what might happen if we replace the pulse wave that forms the basis of the previous sounds with something that is already inherently voice-like. We can investigate this by replacing the Analogue Osc with a Wavetable Osc, selecting the Voice table and choosing a suitable position with it. Figure 17 and sound #9 demonstrate this and, as you can hear, a different – but still very useable – vocal timbre results:

(Click to enlarge)
You might think that you always have to start with a quasi-vocal waveform to obtain a vocal sound, but this is far from true. Take the swarm of giant, angry insects in sound #10 , which was created using the patch in figure 18:
This is the unfiltered output from a Multi Osc with random detune being swept by the Mod Env from a large to a low value at the start of the note, the pitch being swept upward at the same time, and a delayed vibrato being supplied by LFO1. If we now add a Formant Filter to this patch (figure 19) the nature of the sound changes dramatically, becoming vocal in timbre and sounding almost like a male ensemble in a reverberant space, even though no effects have been applied:

(Click to enlarge)

(Click to enlarge)
Other sounds
There are of course many other things we can do with vocal synthesis. Returning to the wavetable oscillator, I have created a new patch with the Gender set to maximum and the X/Y position in the centre of the display. (Figure 20.) I have added four paths in the modulation matrix to refine this, with a touch of vibrato supplied by LFO1, some random pitch deviation supplied by LFO2, a short sweep though part of the wavetable generated by the Mod Env, and an organ-like amplitude envelope generated by the Global Env that curtails every note eight seconds after you play it. (“Ah-ha!” I hear you say.) You might think that the use of a vocal wavetable and a Formant Filter with the Gender set to maximum would produce a female vocal timbre, but instead it emulates the strange tonal quality of a Mellotron. This is because the Mellotron’s tape replay system exhibits strong peaks in its output spectrum, so the use of a formant filter is a good way to imitate this. Sound #12 demonstrates the patch in figure 20 played without external effects:
While sound #13 demonstrates what is possible when ensemble is applied:
(Click to enlarge)
Finally, we come to the famous ‘talking’ synthesiser patch. There are many variants of this, mostly based around the sounds “ya-ya-ya-ya-ya” or “wow-ow-ow-ow-ow”, but they all boil down to moving the formant peaks while the sound is playing. If we had a complex, scientifically accurate synthesiser, we could reproduce genuine vowel sounds, but few if any commercially available synths are capable of this. Figure 21 shows a Thor patch that says “wow” by shifting the Gender, X and Y values by appropriate amounts while opening and closing the audio amplifier. With no external effects applied, we obtain sound #14 from this. Wow!

(Click to enlarge)
Epilogue
To be honest, concentrating on vocal and SynthVox sounds only scratches the surface of formant synthesis, and you can use formant filters to create myriad other sounds ranging from orchestral instruments to wild, off-the-wall effects. But, unfortunately, there’s no space to demonstrate them here because we’ve come to the end of my tutorials introducing Thor’s filters. I hope that they have given you some new ideas and – as I suggested when I concluded my tutorials on Thor’s oscillators – have illustrated why there is so much more to synthesis than tweaking the cut-off knobs of resonant low-pass filters. Thank you for reading; I appreciate it.
Text by Gordon Reid



